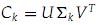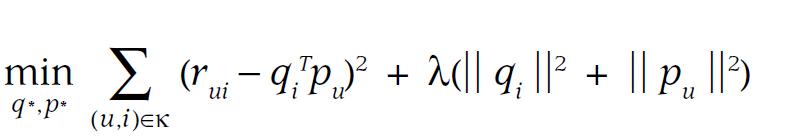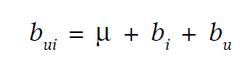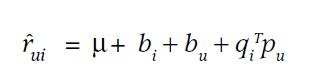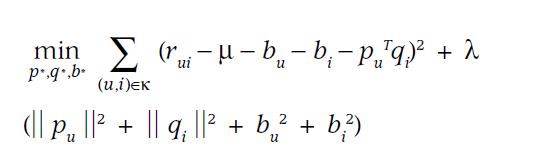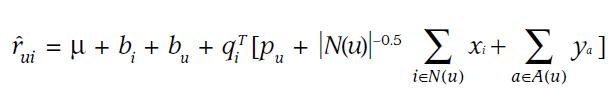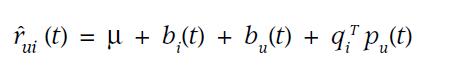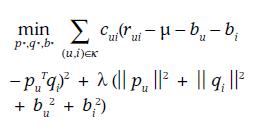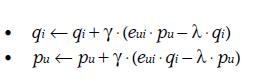由于近期Team内有同学用到bulkload,整理了一下过往我用到的bulkload的相关使用经验hbase 0.90 和0.94 版本做一些简单的分析,可供参考。
1. 概述 官方说明 http://hbase.apache.org/0.94/book/arch.bulk.load.html )
简单的说,bluk load 是能够批量加载hfile => hbase的技术。
1.1. 案例 在2013年的maillog项目中,我们使用了bulk load技术。批量加载了从M/R生成的HFile数据。
加载数据量: HFile(Region) 总数: 100个 450G (snappy压缩后100G )小于 1秒
1.2 特性 a) bulkload 在加载的同时,并不会影响正常读写。(如果写文件造成分区变化,对bulkload有影响)b) bulkload 的加载是秒级的,在同一个HDFS cluster中,会将数据move。c) bulkload 也支持从不同的hdfs cluster copy数据(不同版本没有测试过),同一个版本可行,它会把原来的move操作替换为copy,效率会降低。注意 : 如果你的数据没有move而是copy,请check一下hdfs的URI写的是否正确一致)
1.3. 空表和非空表的策略 场景定义 bulkload 适用于初始化整个HBase表(空表), 也适用于对于增量数据的导入(非空表)
策略 显然,对于这两种场景的操作手法和策略是不同的。效率和影响 效率 指的是如何在短时间内将数据load。影响 指的是如何避免在做bulkload的时候,减少对集群的影响,避免hbase触发split/merge等heavy的操作。
操作手法一般包括: a) HFile的预处理 通过M/R Job或者其他手段预先处理HFile,可以定义HFile大小,splitkey规则,可以在非空表的情况下,极大避免对集群的影响。b) 预分区 通常来说,对于空表的bulkload应该是不会触发集群的split、merge等操作的。通过预分区可以有效的规避这一点。和Hbase 的split size结合使用。
2. Bulkload客户端流程 主要围绕LoadIncrementalHFiles 类来说明基本的流程。http://trgit2/wz68/importdb_blukload/blob/master/src/main/java/com/newegg/email/importdb/bulkload/tool/LoadIncrementalHFiles.java )http://trgit2/wz68/importdb_blukload/blob/master/src/main/java/com/newegg/email/importdb/bulkload/tool/LoadIncrementalHFilesConcurrency.java )
Step 1. main entry LoadIncrementalHFiles的entry方法,会接收两个参数,一个是表的名字,另一个是hfile文件或文件夹路径 (此处可传递文件夹)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// entry 方法
public static void main(String[] args) throws Exception {
int ret = ToolRunner.run(new LoadIncrementalHFiles(HBaseConfiguration.create()), args);
System.exit(ret);
}
// tool的默认加载方法run
public int run(String[] args) throws Exception {
if (args.length != 2) {
usage();
return -1;
}
String dirPath = args[0]; // ---> 路径(文件、文件夹)
String tableName = args[1]; // ---> table name
boolean tableExists = this.doesTableExist(tableName);
if (!tableExists)
this.createTable(tableName, dirPath);
Path hfofDir = new Path(dirPath);
HTable table = new HTable(conf,tableName);
doBulkLoad(hfofDir, table); // ---> 调用bulkload方法
return 0; // ---> Run方法中并没有调用M/R job client,因此只是一个local app,不能算是M/R的job
}
Step 2 . 串行化和并行化 doBulkLoad 串行化和并行化目前已经在高版本应该解决了。
a) 0.90版本的串行化: 以下这段是官方提供的代码,我们可以看到tryLoad是循环的。所以无法并发去做。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public void doBulkLoad(Path hfofDir, HTable table) throws TableNotFoundException, IOException {
HConnection conn = table.getConnection();
if (!conn.isTableAvailable(table.getTableName())) {
throw new TableNotFoundException("Table " + Bytes.toStringBinary(table.getTableName()) + "is not currently available.");
}
Deque<LoadQueueItem> queue = null;
try {
queue = discoverLoadQueue(hfofDir);
while (!queue.isEmpty()) { // ----> 串行化消费队列,提交bulkload
LoadQueueItem item = queue.remove();
tryLoad(item, conn, table.getTableName(), queue);
}
} finally {
if (queue != null && !queue.isEmpty()) {
StringBuilder err = new StringBuilder();
err.append("-------------------------------------------------\n");
err.append("Bulk load aborted with some files not yet loaded:\n");
err.append("-------------------------------------------------\n");
for (LoadQueueItem q : queue) {
err.append(" ").append(q.hfilePath).append('\n');
}
LOG.error(err);
}
}
}
b) 基于0.90版本修改的并行化方案,通过构建线程池来完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public boolean doBulkLoad(Path hfofDir, HTable table) throws TableNotFoundException, IOException {
boolean isSuccess=false;
HConnection conn = table.getConnection();
if (!conn.isTableAvailable(table.getTableName())) {
throw new TableNotFoundException("Table " + Bytes.toStringBinary(table.getTableName()) + "is not currently available.");
}
List<Deque<LoadQueueItem>> queueList = null;
// Deque<LoadQueueItem> queue = null;
queueList = discoverLoadQueue(hfofDir);
int threadNums=conf.getInt(CONCURRENCY_NUMS, 1);
LOG.info("********* thread nums = "+threadNums);
ExecutorService executorService = Executors.newFixedThreadPool(threadNums); // -----> 并行化解决方案
List<Future<Boolean>> resultList = new ArrayList<Future<Boolean>>();
try{
for (Deque<LoadQueueItem> queue : queueList) {
Future<Boolean> future =executorService.submit(new LoadThread(queue, conn, table.getTableName()));
resultList.add(future);
}
for (Future<Boolean> result : resultList) {
if (!result.get(100, TimeUnit.MINUTES)) {
LOG.error("validatorThread return false");
return false;
}
}
isSuccess = true;
}catch(Exception e){
LOG.error(e);
}finally{
executorService.shutdown();
return isSuccess;
}
}
c) 官方0.94的版本的代码片段,已经提供了并行化,并且大幅修改了代码,开启并行化,需要手动设置参数: hbase.loadincremental.threads.max ,默认值是机器的cpu cores相关1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public void doBulkLoad(Path hfofDir, final HTable table)
throws TableNotFoundException, IOException
{
final HConnection conn = table.getConnection();
if (!conn.isTableAvailable(table.getTableName())) {
throw new TableNotFoundException("Table " +
Bytes.toStringBinary(table.getTableName()) +
"is not currently available.");
}
// initialize thread pools ----> 并行化处理加载HFile
int nrThreads = cfg.getInt("hbase.loadincremental.threads.max",
Runtime.getRuntime().availableProcessors());
ThreadFactoryBuilder builder = new ThreadFactoryBuilder();
builder.setNameFormat("LoadIncrementalHFiles-%1$d");
ExecutorService pool = new ThreadPoolExecutor(nrThreads, nrThreads,
60, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(),
builder.build());
((ThreadPoolExecutor)pool).allowCoreThreadTimeOut(true);
......
Step 3. 查看hfile边界,以决定是否需要split 这个地方就是是否会在客户端发生split的原因1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/**
* Attempt to assign the given load queue item into its target region group.
* If the hfile boundary no longer fits into a region, physically splits
* the hfile such that the new bottom half will fit and returns the list of
* LQI's corresponding to the resultant hfiles.
*
* protected for testing
*/
protected List<LoadQueueItem> groupOrSplit(Multimap<ByteBuffer, LoadQueueItem> regionGroups,
final LoadQueueItem item, final HTable table,
final Pair<byte[][], byte[][]> startEndKeys)
throws IOException {
final Path hfilePath = item.hfilePath;
final FileSystem fs = hfilePath.getFileSystem(getConf());
HFile.Reader hfr = HFile.createReader(fs, hfilePath,
new CacheConfig(getConf()));
final byte[] first, last;
try {
hfr.loadFileInfo();
first = hfr.getFirstRowKey();
last = hfr.getLastRowKey();
} finally {
hfr.close();
}
LOG.info("Trying to load hfile=" + hfilePath + ----> 从hfile中得到first 和 last的信息
" first=" + Bytes.toStringBinary(first) +
" last=" + Bytes.toStringBinary(last));
if (first == null || last == null) {
assert first == null && last == null;
// TODO what if this is due to a bad HFile?
LOG.info("hfile " + hfilePath + " has no entries, skipping");
return null;
}
if (Bytes.compareTo(first, last) > 0) {
throw new IllegalArgumentException(
"Invalid range: " + Bytes.toStringBinary(first) +
" > " + Bytes.toStringBinary(last));
}
int idx = Arrays.binarySearch(startEndKeys.getFirst(), first, ---> 从整个集群的statEndKeys的多列中搜索是否满足该HFile的Region
Bytes.BYTES_COMPARATOR);
if (idx < 0) {
// not on boundary, returns -(insertion index). Calculate region it
// would be in.
idx = -(idx + 1) - 1;
}
final int indexForCallable = idx;
boolean lastKeyInRange =
Bytes.compareTo(last, startEndKeys.getSecond()[idx]) < 0 ||
Bytes.equals(startEndKeys.getSecond()[idx], HConstants.EMPTY_BYTE_ARRAY);
if (!lastKeyInRange) {
List<LoadQueueItem> lqis = splitStoreFile(item, table, ---> 如果不满足,就会触发客户端split,调用splitStoreFile方法这里就时效率慢的原因!!!!
startEndKeys.getFirst()[indexForCallable],
startEndKeys.getSecond()[indexForCallable]);
return lqis;
}
// group regions.
regionGroups.put(ByteBuffer.wrap(startEndKeys.getFirst()[idx]), item); ---> 如果HFile满足区间,或者是已经将不满足区间的HFile切分满足,那么就加到RegionGroup中,等待加载.
return null;
}
Step 4. 客户端split的两个方法 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
// 决定split的范围,数量,分区
protected List<LoadQueueItem> splitStoreFile(final LoadQueueItem item,
final HTable table, byte[] startKey,
byte[] splitKey) throws IOException {
final Path hfilePath = item.hfilePath;
// We use a '_' prefix which is ignored when walking directory trees
// above.
final Path tmpDir = new Path(item.hfilePath.getParent(), "_tmp");
LOG.info("HFile at " + hfilePath + " no longer fits inside a single " +
"region. Splitting...");
String uniqueName = getUniqueName(table.getTableName());
HColumnDescriptor familyDesc = table.getTableDescriptor().getFamily(item.family);
Path botOut = new Path(tmpDir, uniqueName + ".bottom");
Path topOut = new Path(tmpDir, uniqueName + ".top");
splitStoreFile(getConf(), hfilePath, familyDesc, splitKey,
botOut, topOut);
// Add these back at the *front* of the queue, so there's a lower
// chance that the region will just split again before we get there.
List<LoadQueueItem> lqis = new ArrayList<LoadQueueItem>(2);
lqis.add(new LoadQueueItem(item.family, botOut));
lqis.add(new LoadQueueItem(item.family, topOut));
LOG.info("Successfully split into new HFiles " + botOut + " and " + topOut); // 如果split成功,我们会看到这些日志...
return lqis;
}
// 真正调用执行split,copy....
/**
* Split a storefile into a top and bottom half, maintaining
* the metadata, recreating bloom filters, etc.
*/
static void splitStoreFile(
Configuration conf, Path inFile,
HColumnDescriptor familyDesc, byte[] splitKey,
Path bottomOut, Path topOut) throws IOException
{
// Open reader with no block cache, and not in-memory
Reference topReference = new Reference(splitKey, Range.top);
Reference bottomReference = new Reference(splitKey, Range.bottom);
copyHFileHalf(conf, inFile, topOut, topReference, familyDesc); -----> 客户端split的真正copy的方法
copyHFileHalf(conf, inFile, bottomOut, bottomReference, familyDesc);
}
3. Q&A 1) Q: 目前的工具是否是并行化加载? 通过上面的分析,我们可以看到,从0.94开始就已经是有并行化处理了,因此我们不需要再像我之前的那种方式去做了。只要定义好自己的线程池大小就ok.
但我们也需要注意的是,由于**LoadIncrementalHFiles** 工具并不是M/R job,所以不要指望能直接通过M/R来提高效率。
2) Q: 如果避免split? split有两个定义。一个是客户端的split,另一个是Region Server的split。
在空表情况下,通过预分区的方式,只要key分的准确,就不会触发客户端的split。结合hbase 原本的 split size 参数,使HFile对应的HRegion大小合适,不会造成RSr的split.
3) Q: 对空表的bulkload的过程中,可否正常读写? 读肯定是没有问题的,写的话,如果数据量不大,不触发Region的split,则也没有关系。
4) Q: 为什么bulkload的过程中,在数据已经准备的情况下,效率那么快,秒级别加载,并且不会disable Region? 前面只分析了Bulkload的客户端代码,如果去翻阅一下服务端代码我们可以知道。对于RS来说,bulkload就两件事情,第一件是mv文件,第二件是在RS的memory里加上新HFile的meta信息。
5) Q: 对于非空表的增量数据bulkload,基本策略有哪些? 参考步骤如下:
a) 对新增HFiles大小做预估计,如果当前cluster可以容纳,则不需要预分区,否则,可以先预分区。
b) 通过M/R对HFile做符合当前集群分区情况进行切分。
c) 加载。
对此,官方设计中有一段说明:
大致意思是,即使客户端工具能够完成split的工作,但并不是最有效的方式,用户应该注意边界问题。
作者:3h_williamhttps://github.com/3h-william http://3h-william.github.io
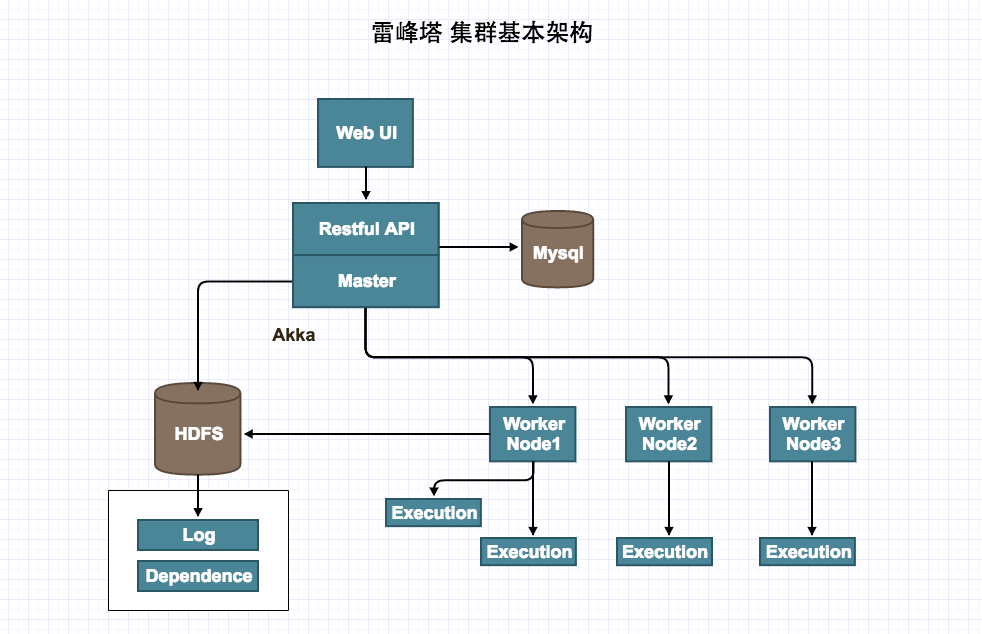
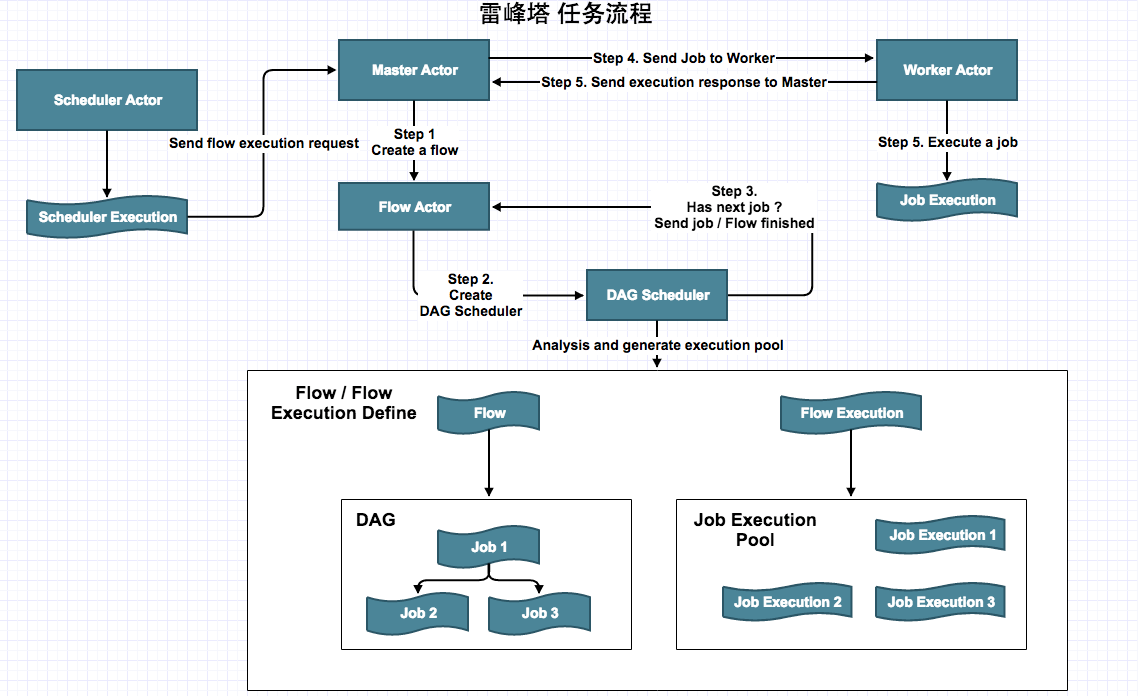
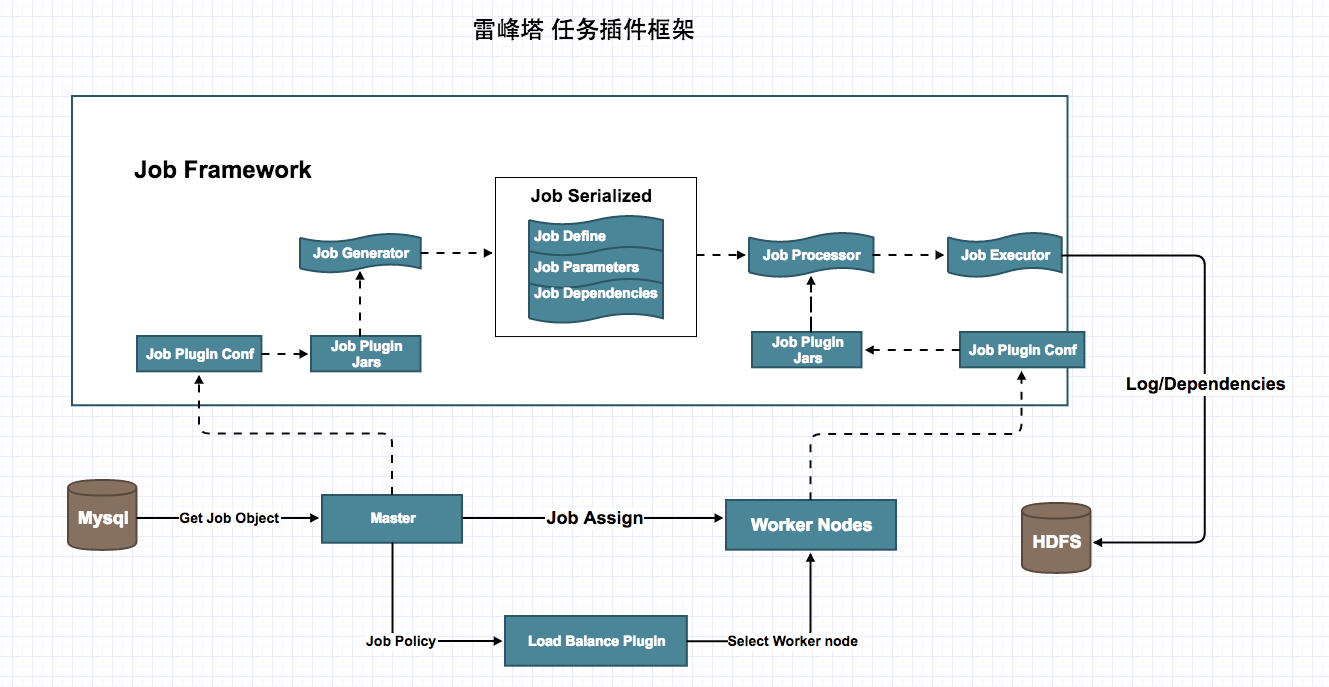
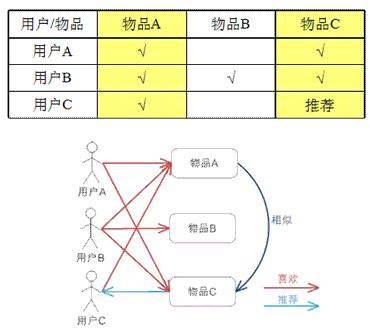
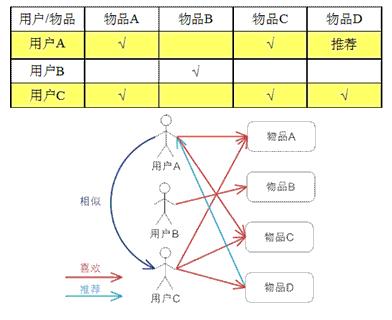
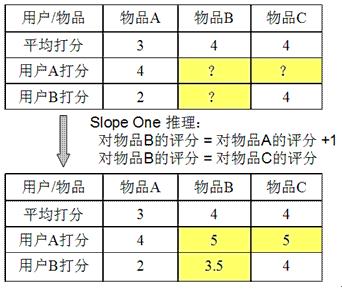
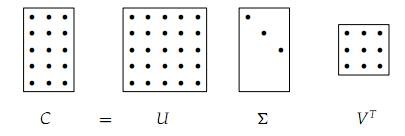
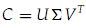
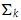 ,它是将
,它是将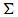 的第k+1行至M行设为零,也就是把
的第k+1行至M行设为零,也就是把