背景
前一段时间,内部用到TSDB,发现经常引起HBase服务挂掉。最终,我这里经过一些排查,找到了问题。
并且,我们已经向社区提出了这个问题。在这里,以此记录解决过程。
一. 根本原因:
因为TSDB的合并导致单条记录的column非常大。一旦大于MAX_CHUNK_SIZE_KEY = “hfile.index.block.max.size”(默认128K); 就由一定几率使得Memstore Flush无限进行。
并且本地已经模拟出该场景。我插入了一条Column非常大的记录(150K) ,然后调用flush, RS进入死循环,HDFS文件不断增大.
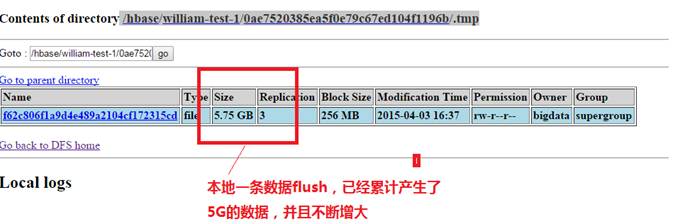
二. 大致分析流程如下
1.今天再次走代码流程和日志记录,纠正了昨天判断是HBase Compaction触发导致的问题。(出问题的那个点,并没有进行HBase层面的Compact)
2.进一步确认,是因为HBase的Memstore Flush成HFile导致。 (Hfile也是存在于Region/.tmp中,在一个时间点,HBase都做了一次flush
3.随后定位到,问题出在了Flush Memstore的时候,需要生产HFile V2 下的BlockData Index, 并导致写索引的死循环。
接着,让我们来看看,代码究竟做了些什么事情:
a)选取第一条KV,作为RootChunk,建立索引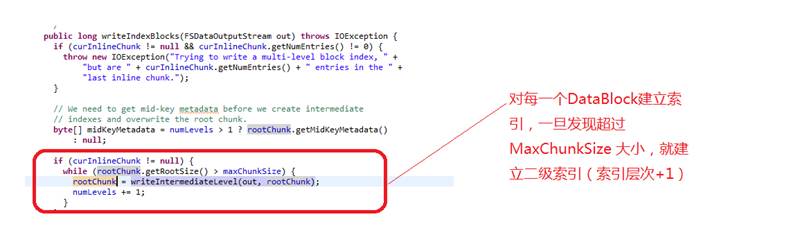
b)写完Level Two的索引数据,但是还是要将Parent的索引写到Level One的索引中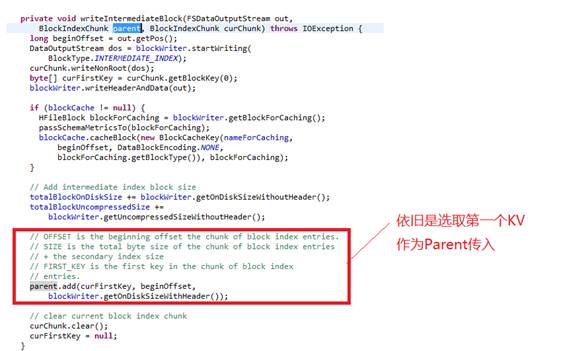
c)进入a图中的死循环。 反复调用写Root KV的索引,但都因为length太大,再次写子索引,周而复始,至死不休。
三. 社区反映
https://issues.apache.org/jira/browse/HBASE-12320
这是去年在JIRA 上提出的 ISSUE,但一直都没有得到解决。虽然已经有人意识到了问题。
事实上,不论是ColumnName的大小,或是Rowkey的大小,或是Faimily的大小,一旦超过这个阀值,就会出问题。
同时,只是建议,HBase的单个KV的大小,不超过128K。
四. 解决方案
注意TSDB的推送的数据,不要分的太小。或者,关闭compaction(TSDB层面)
作者:3h_william
联系: https://github.com/3h-william
出处:http://3h-william.github.io